LABORATORY熱の実験室
- 熱の実験室
- 熱の実験室-新館
■ 機械学習
下記のツールで、データ準備と機械学習のモデルを作成しました。
下記のツールで、データ準備と機械学習のモデルを作成しました。
- プログラミング言語: Python
- 機械学習ソフトウェアライブラリ: TensorFlow・Keras
- プログラミング環境: Jupyter Notebook または Colab
- データの準備
「教師あり学習」の手法で機械学習を行うため、写真とラベルデータを用意しました。まずワークをコンベアに乗せ、ラズベリーパイで「焼成前」・「焼成中」・「焼成後」の写真を撮りました。その後、焼けている写真には「1」、焼けていない写真には「0」のラベルを付けました。集めたデータを、(a)トレーニング用、(b)検証用、(c)テスト用に、それぞれ 75%、15%、10% の比率で、ランダムにフォルダへ分けました。機械学習は、通常膨大なデータの用意が必要です。しかし今回は、「焼けている」か「焼けていないか」の2種類のみの簡単な判別であるため、少量のデータで学習を行いました。データが足りず、学習が失敗した時は、写真データ数をプログラムで増やして補いました。また、データの軽微な編集、改造(Data Augmentation)、複製作業も行いました図6:写真データとラベル
- 機械学習のモデル
今回は、簡易的な深層ニューラルネットワークでモデルを作成しました(図7)。第一層(flatten)は、2次元画像を一次元に変換する層。第二層のニューロンネットワーク(dense)は、活性化関数「ReLU」を用いた、512個の演算ユニットで作成しました。第三層(dense_1)は基本的には第二層と同じですが、演算ユニットは256個に設定しました。この演算ユニットの数と活性化関数の種類は、次の「3.モデルの学習」の結果を確認しながら調整し、最も良い結果になったものを選択しました。また、最後のレイヤー(dense_2)は「焼けている」か「焼けていない」かの予測の確率を出力するために、演算ユニットは2個で、活性化関数は「softmax」を用いて作成しました。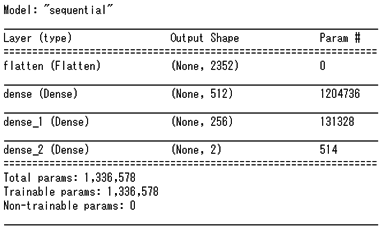
図7:モデルのサマリー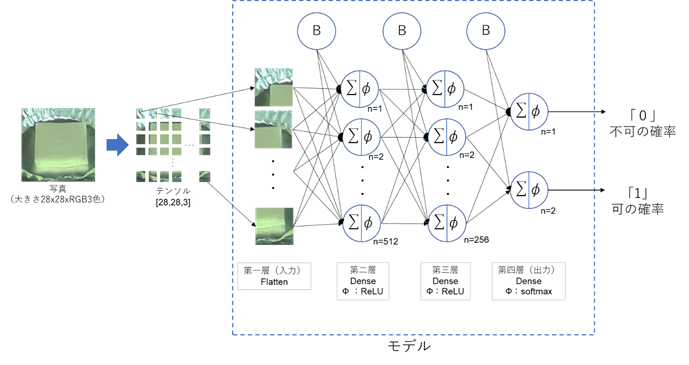
図8:モデルのイメージ - モデルの学習
トレーニングと検証用のデータで、50サイクル(Epoch)の学習を行いました。モデルの学習は、「Sparse Categorical CrossEntropy」のロス(予測と正解の差を表すパラメーター)と「Nadam」の最適化手法で行いました。トレーニングと検証、それぞれのデータセットにあるロスと正解率を出しました(図9)。ロスと正解率からモデルを評価し、レイヤーまたは演算ユニットの数を調整しました。
試したことのないテストデータを用いて、学習したモデルを評価した結果、ロスは0.4016、正解率は96%でした。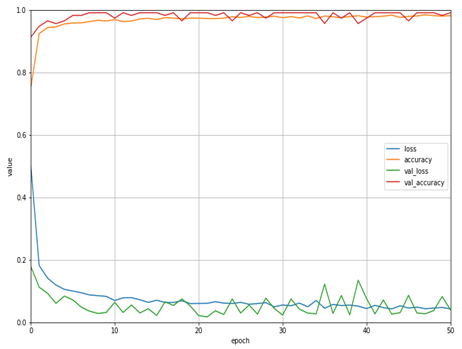
図9:ロスと正解率(青:トレーディングロス、橙:正解率、緑:検証ロス、赤、正解率 - モデルの軽量化とラズベリーパイへの展開
TensorFlowのモデルを軽量化するため、TensorFlow Liteを用いました。学習したモデル(.pb形式)をTensorFlow Liteの形式(.tflite)に変換し、ラズベリーパイに展開しました。コンベアに流して焼いたワークを撮影した写真から焼き加減を判定し、自動的にテスト炉のコンベアを動かすプログラムを作成しました。